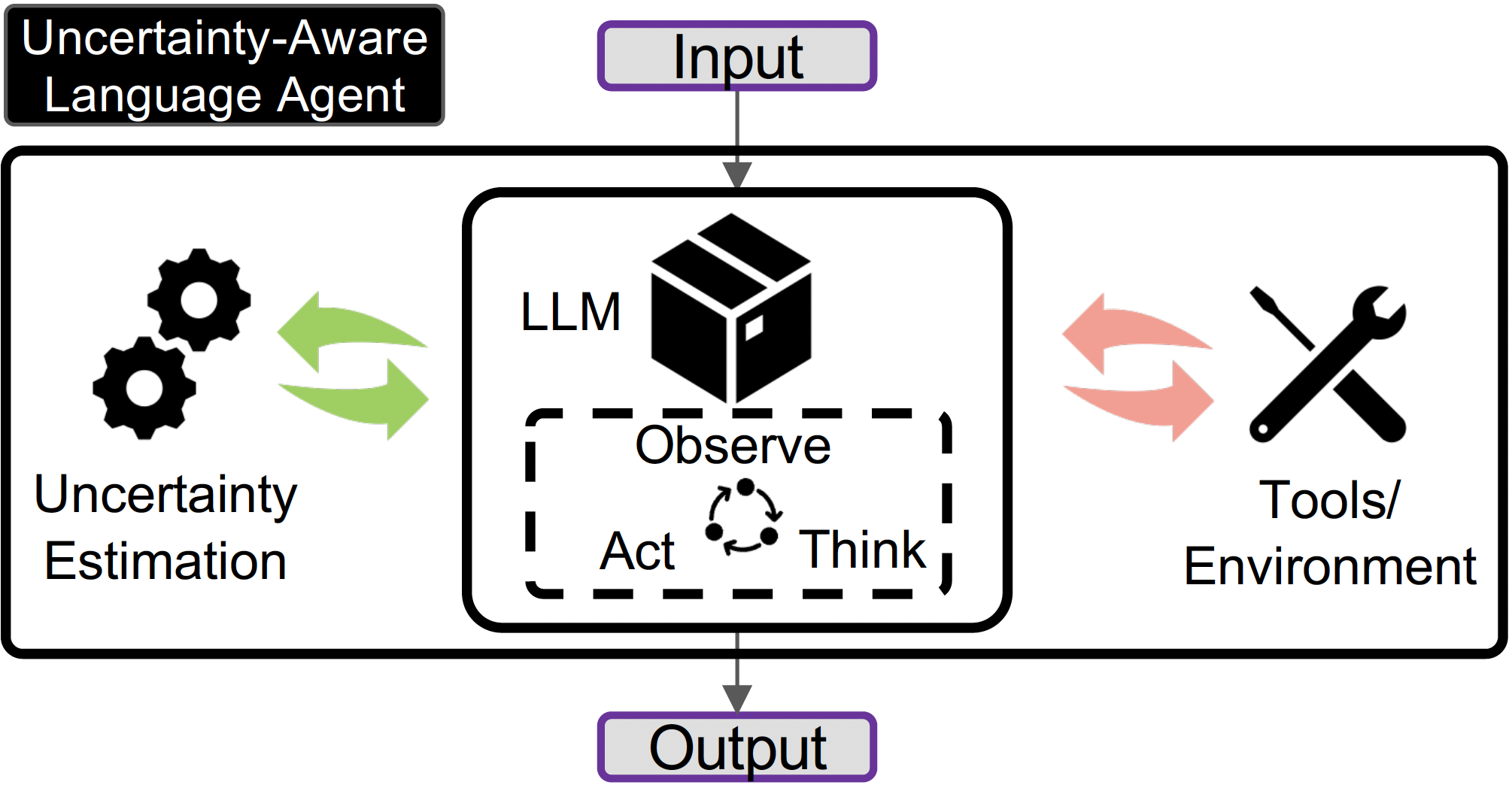
While Language Agents have achieved promising success by placing Large Language Models at the core of a more versatile design that dynamically interacts with the external world, the existing approaches neglect the notion of uncertainty during these interactions. We present the Uncertainty-Aware Language Agent (UALA), a framework that orchestrates the interaction between the agent and the external world using uncertainty quantification. Compared with other well-known counterparts like ReAct, our extensive experiments across 3 representative tasks (HotpotQA, StrategyQA, MMLU) and various LLM sizes demonstrates that UALA brings a significant improvement of performance, while having a substantially lower reliance on the external world (i.e., reduced number of tool calls and tokens). Our analyses provide various insights including the great potential of UALA compared with agent fine-tuning, and underscore the unreliability of verbalised confidence of LLMs as a proxy for uncertainty.

Examples of single-inference UALA trajectories from HotpotQA. Example (a) illustrates the trajectory where CoT answer falls inside the certainty region. Example (b) is the trajectory where CoT is too uncertain and tool is activated, arriving at a final response which falls in the acceptable certainty region (denoted by UALA-S and UALA-M in our results). Example (c) is the trajectory where both CoT and tool-generated responses are considered uncertain, and the agent asks help from human (denoted by UALA-S+Oracle in our results).
Uncertainty estimation methods are broadly categorised into two types: single-inference based and multi-inference based.
Single-inference. Single-inference uncertainty estimation calculates the uncertainty based on one output, necessitating access to the token log-probabilities within that output. The methods vary based on the answer being a single-token (e.g., yes or no) or free-form (multi-token) format.
Multi-inference. Multi-inference uncertainty estimation calculates the uncertainty of an answer based on multiple outputs from an LLM, eliminating the need for individual token log-probabilities.
Uncertainty Threshold. The decision to accept an answer or resort to alternative mechanisms hinges on the level of uncertainty associated with that answer. We propose different ways of setting the uncertainty threshold for single-inference and multi-inference uncertainty estimation. For single-inference, we adopt a subset of the training data to create a calibration set. The uncertainty threshold is estimated based on the calibration set. For the estimation of uncertainty threshold in multi-inference setting, we adopt the same subset of the training data as the calibration set. We use the average uncertainty of the answers in the calibration set as the threshold.
For the details about uncertainty estimation section in UALA, please refer to our paper.
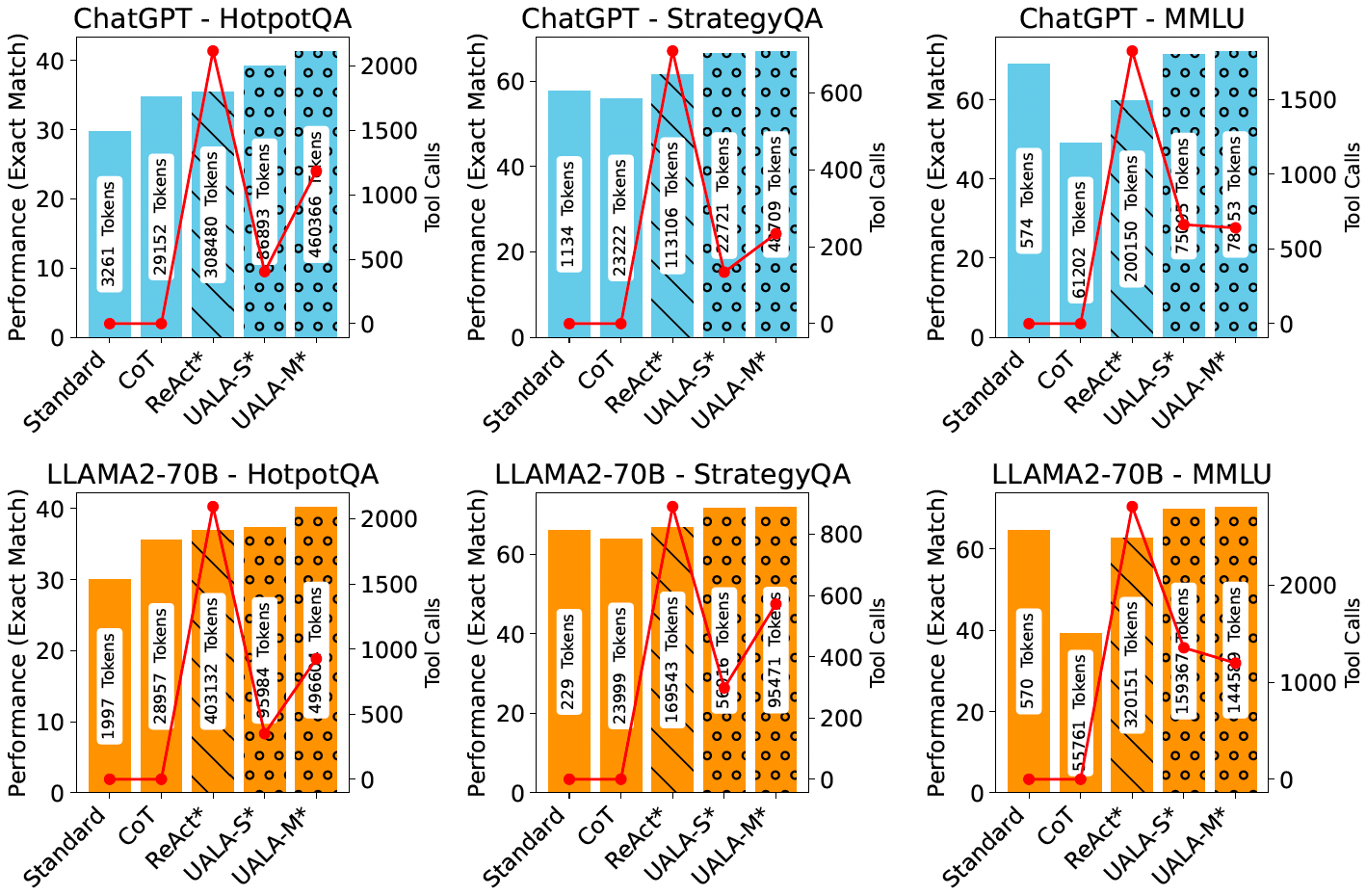
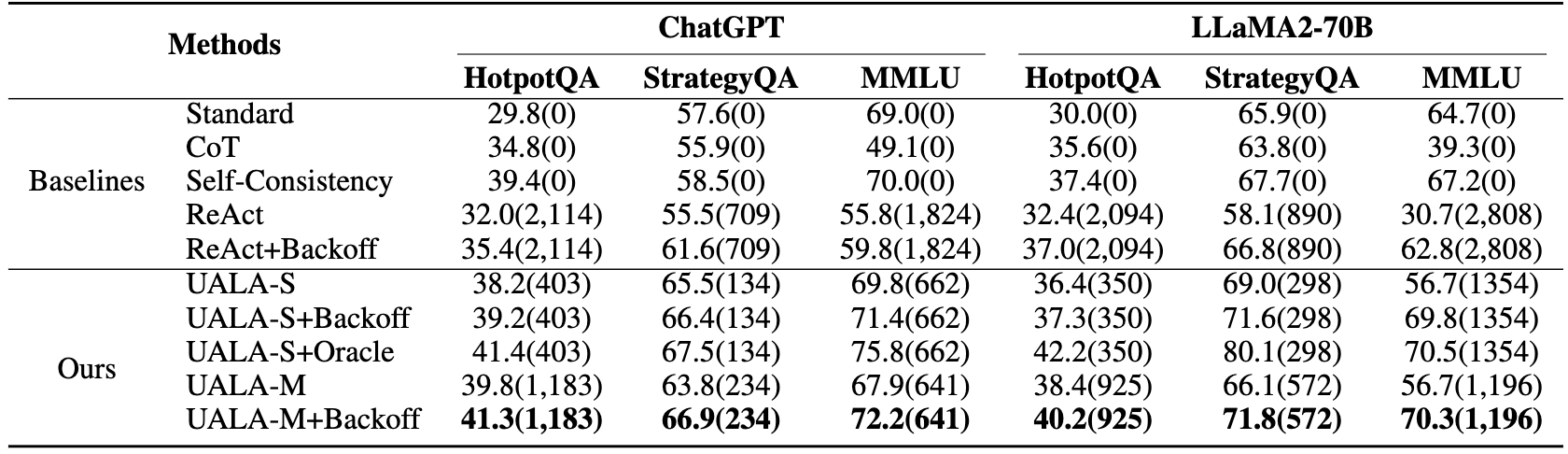
(1) CoT outpeforms Standard on HotpotQA, while Standard excels on StrategyQA and MMLU. Self-Consistency consistently enhances results across three datasets and two LLMs. ReAct, when used for every instance, underperforms Standard/CoT/Self-Consistency. With the integration of backoff, ReAct+Backoff shows improvement but is generally still falls behind Self-Consistency, highlighting the benefit of SC's sampling and majority voting as a proxy for capturing uncertainty.
(2) UALA-S significantly betters ReAct's performance, cutting tool use by over half, and surpasses Standard/CoT across all datasets. UALA-M achieves similar performance to UALA-S but with increased tool use. UALA-S+Backoff outperforms ReAct+Backoff and often exceeds Self-Consistency with UALA-M+Backoff delivering the best results in all settings on three datasets.
(3) The largest gain in improvement by UALA is observed for HotpotQA (free-form), followed by StrategyQA (binary), and MMLU (multiple choice). This is expected as the free-form response space is much larger and diverse, compared with MCQ type of questions. The difference in gain could be explained in terms of the amount of uncertainty divergence between correct and incorrect answers in each task.
(4) The average (single-inference and multi-inference) EM improvement for ChatGPT with LLaMA2-70B compared to Standard/CoT results: ChatGPT gains 11.7% and LLaMA2-70B gains 8.9%. This could be an indication that ChatGPT is likely to produce better-calibrated probability estimates, leading to a more reliable uncertainty estimation on training set that generalizes to test set. This could be an artefact of the two models' difference in size and training protocol.
(5) The results from UALA-S+Oracle underscore an additional aspect of the value of uncertainty. This feature is particularly crucial in sensitive domains, as it can deter the agent from generating incorrect responses. Instead of risking an erroneous answer, the agent defers to human (we simulate this by using gold answer) when the response uncertainty is still high after tool activation.
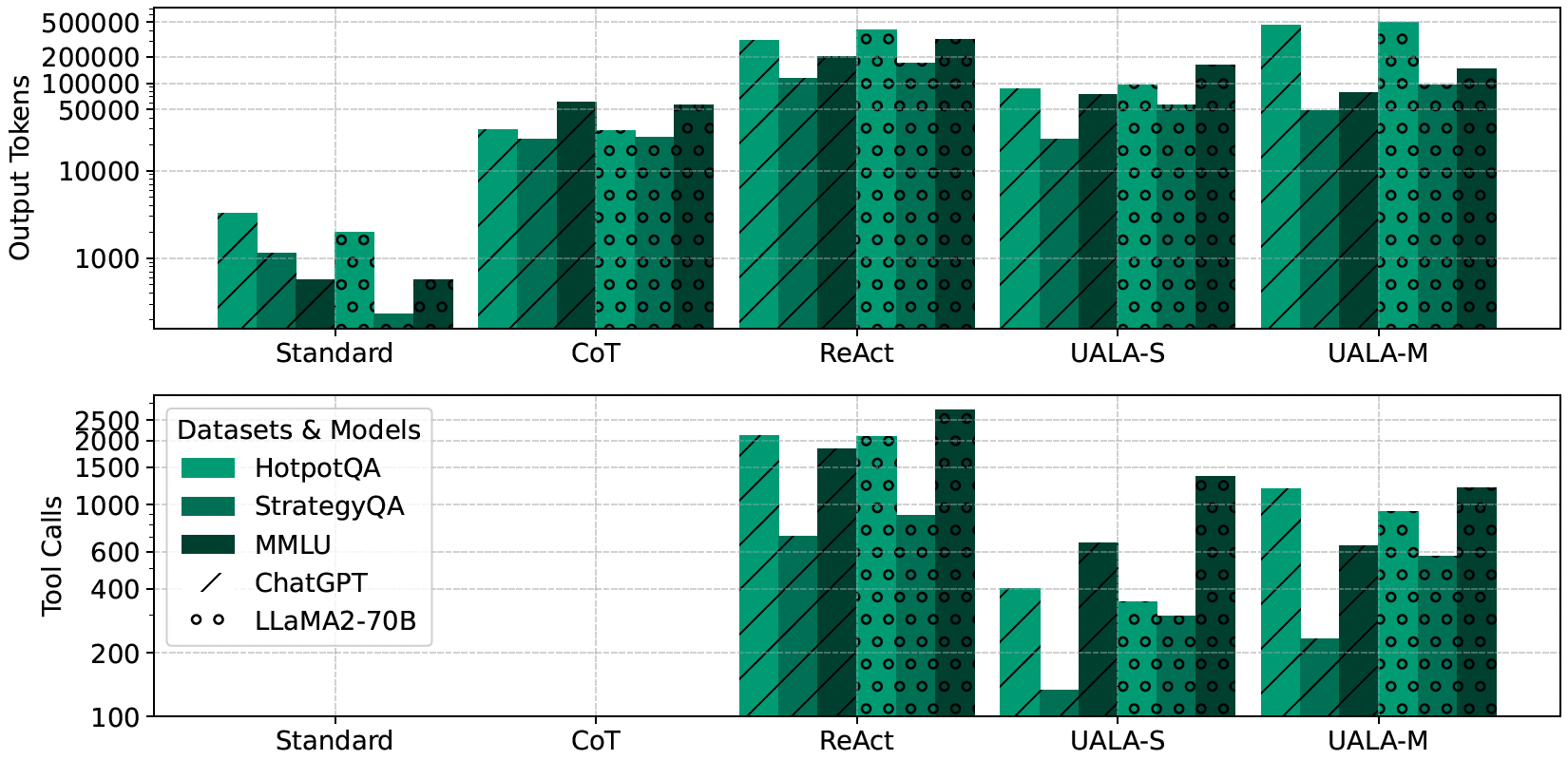
ReAct consumes substantially more (5×) output tokens than CoT. Compared with ReAct, UALA-S reduces the number of output tokens by more than 65%. UALA-M consumes more output tokens as it relies on multiple inference. Both UALA methods can substantially reduce tool calls more than 50% compared with ReAct, making them much more resource-efficient.
| Standard | CoT | ReAct | UALA-S | |
|---|---|---|---|---|
| ChatGPT | 0.5s/it | 1s/it | 12s/it | 3s/it |
| LLaMA2-70B | 50s/it | 50s/it | 180s/it | 70s/it |
| LLaMA2-13B | 25s/it | 25s/it | 120s/it | 45s/it |
| LLaMA2-7B | 20s/it | 20s/it | 100s/it | 35s/it |
Standard and CoT prompting methods do not involve an external tool call, hence faster inference time compared to other methods. As indicated, UALA-S given its selective tool call, has a much lower inference time compared with ReAct. This highlights a practical benefit of using uncertainty to reduce the number of token usage and tool calls, while still providing a significant gain in performance.
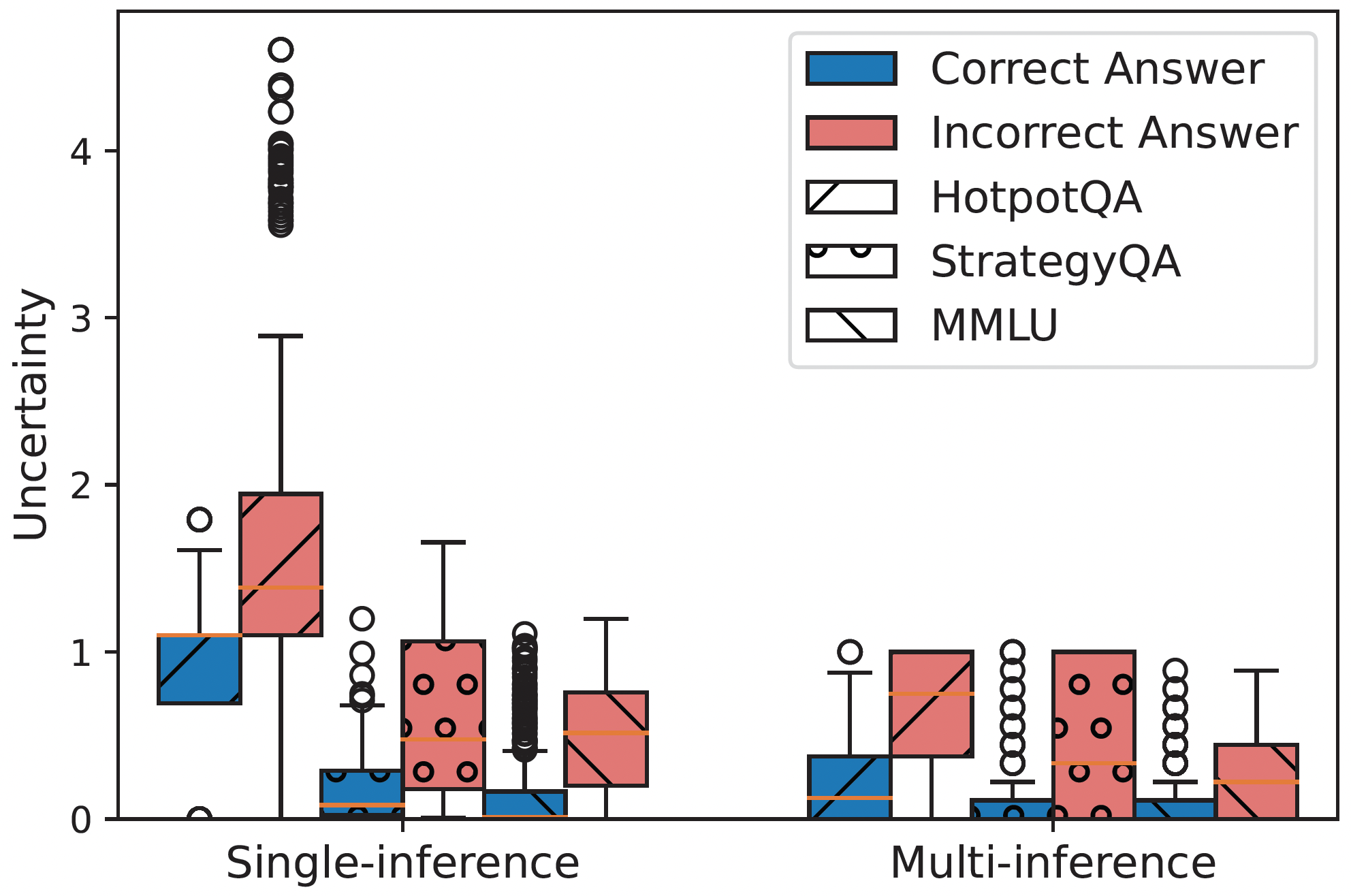
In both single-inference and multi-inference settings, correct answers consistently exhibit lower uncertainty compared to incorrect ones. This difference is statistically significant. When calculating the difference between the average uncertainty of correct and incorrect answers we observe the largest difference to belong to HotpotQA, followed by StrategyQA, and MMLU. This explains why the gain from UALA follows the same pattern in the main results.
| Tasks | Methods | Training Size | ChatGPT | LLaMA2-70B |
|---|---|---|---|---|
| HotpotQA | FireAct | 162 | 27.8 | 27.8 |
| FireAct | 512 | 33.8 | 30.0 | |
| ReAct | No fine-tuning | 32.0 | 32.4 | |
| UALA-S | No fine-tuning | 38.2 | 36.4 | |
| StrategyQA | FireAct | 283 | 60.7 | 63.8 |
| FireAct | 567 | 64.9 | 64.6 | |
| ReAct | No fine-tuning | 55.5 | 58.1 | |
| UALA-S | No fine-tuning | 65.6 | 69.0 | |
We demonstrate the comparison between UALA-S and fine-tuning language agents following the FireAct setting. For ChatGPT, we use the official GPT-3.5-Turbo fine-tuning API; for LLaMA2-70B, we use LoRA. To have a side-by-side comparison, we use the same 500 training samples used for the calibration set, to construct the fine-tuning data. Mimicking the FireAct setting, we ran the 500 examples using ReAct with ChatGPT, and collected the successful trajectories as the training data for FireAct. This amounted to 162 training examples for HotpotQA and 283 for StrategyQA. In addition, to match the amount of training data as FireAct setting, we also ran an additional 1000 examples to increase the amount of successful training trajectories to 512 for HotpotQA and 567 for StrategyQA.
Interestingly, on HotpotQA using 162 training examples, FireAct under-performs the few-shot (6-shots) ReAct agent, while it outperforms ReAct on StrategyQA using 283 training examples. Increasing the amount of training data to 500+ leads to improvement on both LLMs with fine-tuned ChatGPT-based agents outperforming the ReAct counterpart on both datasets. Our method, UALA-S, achieves the best result without any fine-tuning and using only the 500 samples for creating the calibration set. This capitalises an obvious empirical advantage for utilising uncertainty instead of fine-tuning in the presence of small amount of data.
@misc{han2024uncertaintyaware,
title={Towards Uncertainty-Aware Language Agent},
author={Jiuzhou Han and Wray Buntine and Ehsan Shareghi},
year={2024},
eprint={2401.14016},
archivePrefix={arXiv},
primaryClass={cs.CL}
}